小規模言語モデル(SLM)のファインチューニング:少ないリソースでのパフォーマンス向上
AI生成AI2024-12-03

生成AIの急速な普及が、世界中の業界に変革をもたらしています。マッキンゼーの2024年のレポートによると、AIの導入率は企業の72%に達し、65%が少なくとも1つの業務において生成AIを定期的に利用していると報告しています。
このような急速な成長は、コスト効率が高く、カスタマイズ可能で、プライバシーを重視した、小規模なオープンソースの大規模言語モデル(LLM)のようなソリューションの必要性を浮き彫りにしています。しかし、弊社のベンチマークテストの結果でも明らかになったよう、これらのモデルは、大規模なモデルに比較して性能が劣ることが多いという課題があります。本日は、この課題に対処するため、ファインチューニングとプロンプト最適化に着目しました。
オープンソースの小規模言語モデルとは?
オープンソースの小規模言語モデルは、パラメータ数が100億未満の公開されているAIモデルです。一般的なPCのような標準的なハードウェア上で展開することが可能です。この利便性により、技術リソースが限られた組織や個人にとって魅力的な選択肢となります。
主な利点
- コスト効率: 一般的なシステム上で動作可能。リソース要件が最小限であるため、コスト削減
- カスタマイズ性: 特定のタスクに合わせて微調整可能。カスタマイズされたソリューションを提供
- プライバシー保証: ローカルに展開されるため、外部APIの必要がなく、データセキュリティが確保
本検証では、Qwen 2.5-7B (Alibaba)、Llama 3.1-8B、Llama 3.2-3B (Meta)の3つの一般的な小規模オープンソースモデルの最適化に焦点を当てます。
小規模モデルのRAG性能評価
Recursive独自の評価ツールである Flow Benchmark Tools を用いて、実社会における実際のシナリオを反映するよう、モデル評価を実施しました。このベンチマークでは、日本政府が公表しているあらゆる文書と、難易度の高い質問を用いて、以下の2つの重要な機能を厳密に評価しました。
- RAG(Retrieval-Augmented Generation)を用いた質問応答
- 文書全体の分析
Flow Benchmark Toolsは、英語と日本語の両言語に対応しており、評価システムは、0(最低)から10(最高)までの値を持つ平均意見評価を出力します。
プロンプト最適化:低コストでの改善
AIモデルへの指示語であるプロンプトを工夫することで、モデルの生成する回答の質を向上させることを「プロンプト最適化」と言います。これは、モデル自体を変更することなく、より正確で有用な情報を引き出すための効果的な手法です。特に、モデルへの指示を具体的にしたり、質問の仕方を工夫したりすることで、モデルの理解度を高めることができます。
私たちの検証では、文書全体を分析するタスクに焦点を当て、プロンプト最適化の効果を検証しました。文書から必要な情報を抽出するRAGという技術は、検索の精度が非常に重要であり、プロンプトの調整による改善は限定的であると考えられるためです。
1. クエリの配置による精度向上
プロンプト内でのクエリの配置が、モデルの回答制度に大きな影響を与えることがわかりました。例えば、Qwen 2.5-7Bモデルにおいて、ドキュメントの後にクエリを配置したところ、スコアが6.35から6.88に改善されました。この結果、プロンプトを適切に設計することが、モデルのパフォーマンス向上に不可欠であることを示しています。
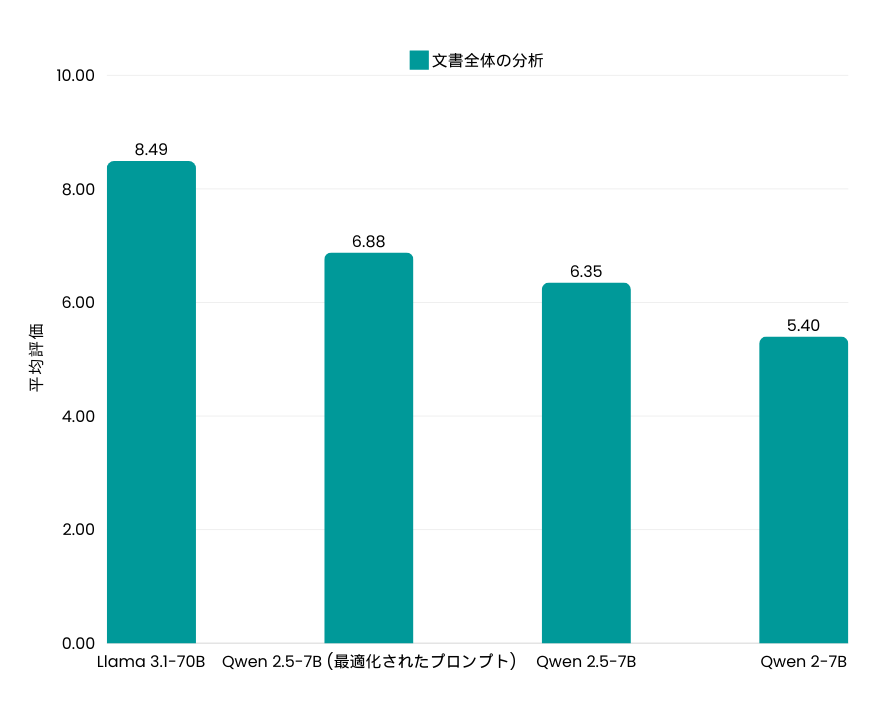
2. ハルシネーションへの対応
AIモデルが、存在しない情報や事実と異なる内容をあたかも正しいかのように生成してしまうことを、ハルシネーションといいます。例えば、架空のウェブサイトのURLを生成したり、与えられたデータに存在しない情報を提供したりする現象です。特に、文書の内容を正確に理解し、分析するようなタスクにおいては、このハルシネーションは大きな問題となります。
Llama 3.1-8Bの検証では、軽微なプロンプト調整だけでは、ハルシネーションを効果的に抑制することはできませんでした。しかし、DSPyから採用した構造化されたプロンプトを使用することで、状況は一変しました。この構造化されたプロンプトは、入力する情報の種類や出力の形式を明確に定めており、モデルが生成する回答の一貫性と正確性を大幅に向上させます。その結果、モデルのスコアは4から8へと大きく改善されました。
構造化データプロンプト (DSPyより採用):

カスタムデータセットによるLLMのファインチューニング
事前学習済みの大規模言語モデル(LLM)を、特定のタスクに特化させるために、そのタスクに合わせたデータを学習させることを「ファインチューニング」と言います。LoRA (Low-Rank Adaptation)という手法を用いることで、元のモデルのパラメータを大幅に変更せずに、新しい知識を学習させることができます。LoRAは、既存のモデルにに小さな調整可能なモジュールを追加することで、メモリ使用量を抑えつつ、効率的のファインチューニングを行うことができます。
この検証では、Flow Benchmarkの指示スタイルを模倣したデータセットを作成し、Llama 3.1-8BおよびLlama 3.2-3Bに対してファインチューニングを行いました。その結果、タスクによってモデルの性能が異なることがわかりました。
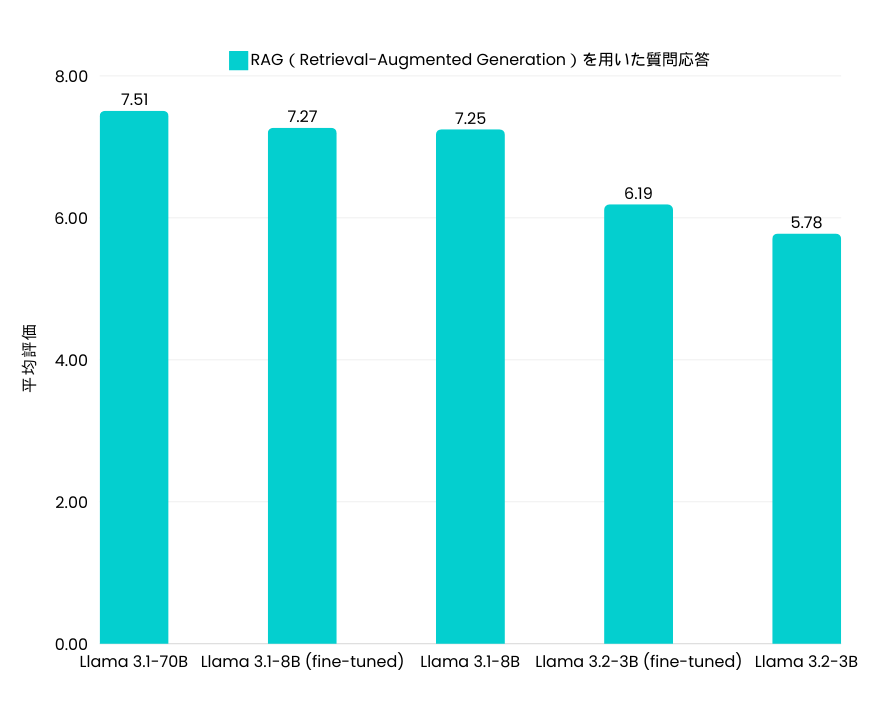
1. RAGを用いた質問応答
- Llama 3.1-8Bでは改善が僅か
- Llama 3.2-3Bは7%の改善を達成
このファインチューニングでは、モデルの性能向上は限定的でした。これは、タスクが情報検索能力に大きく依存しており、モデルがすでにこの能力を十分に備えていたためです。また、ここで行われたファインチューニングは、新しい知識の学習より、指示への対応能力の向上に重点を置いていたことも要因の一つです。結果、Llama 3.1-8BはすでにLlama 3.1-70Bのような大規模モデルと同等の性能を持っていたため、さらなるファインチューニングによる有意な改善は見られなかったです。
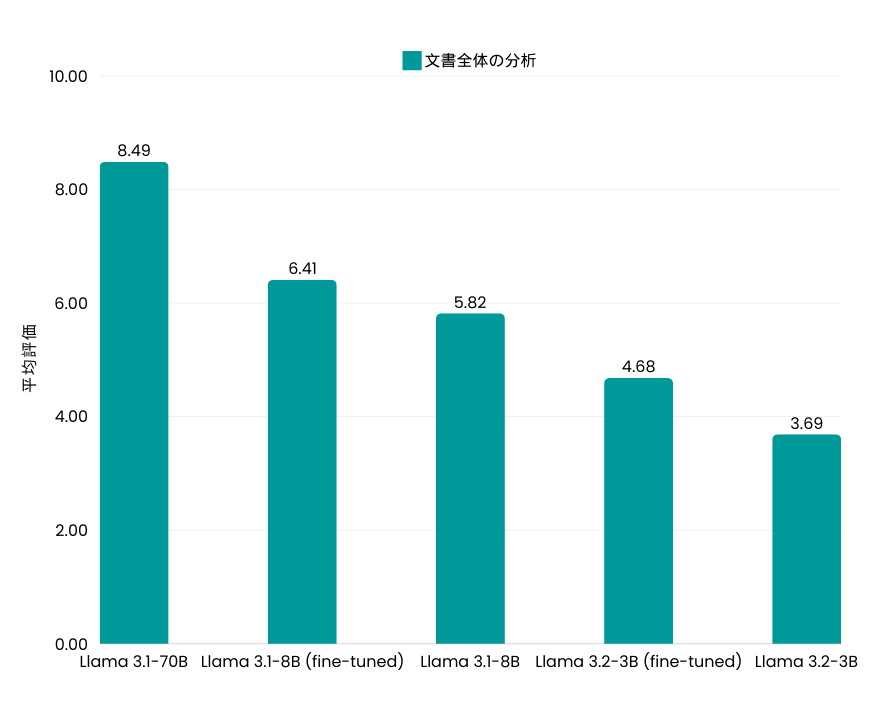
2. 文書全体の分析
- Llama 3.1-8Bは10%の改善
- Llama 3.2-3Bは26%の向上を達成
ファインチューニングにより、モデルがドキュメント分析に必要な深い理解と柔軟な対応能力を獲得した結果、評価スコアが大幅に向上しました。
主なポイント
本検証では、オープンソースの小規模言語モデルのパフォーマンスを最大限に引き出すための、ファインチューニングとプロンプト最適化の重要性を強調しています。
- プロンプト最適化: 構造化されたデータを用いたプロンプトが効果的であることがわかりました。プロンプト設計は、モデルのパフォーマンス向上に大きく貢献する可能性を秘めています。しかし、生成される内容の信憑性、特にハルシネーションの問題を完全に解決するには至っておらず、汎用的なアプローチとは言えません。
- ファインチューニング: タスクに特化したデータセットを用いることで、モデルの性能を大幅に向上させることができます。例えば、ドキュメント分析のような複雑なタスクでは大幅な改善をもたらし、より正確で信頼性の高い出力を実現しました。
これらの手法をを組み合わせることで、小規模なモデルでも、大規模モデルに匹敵する性能を実現し、同時にコスト削減、カスタマイズ性の向上、そしてデータプライバシーの確保が可能になります。
Recursiveでは、オープンソース技術を通じて、AIを誰もが利用できるものとし、企業がより公平で持続可能なソリューションを構築できるよう支援しています。私たちのツールが、貴社のAI戦略をどのように革新し、ビジネスを加速できるか、詳細を知りたい方は sbdm@recursiveai.co.jp までお問い合わせください。
Author

マーケティング・広報担当
Alina Paniuta
ウクライナ出身のアリーナは、台湾の国立政治大学で国際コミュニケーションの修士号を取得しました。台湾で4年間マーケティングマネージャーとして働いた後、2024年にRecursiveチームに加わり、憧れの国、日本での生活を体験するために日本に移住しました。



