Flow Benchmark結果発表:最優秀オープンソースLLMモデル
AI2024-11-05

Recursiveは、最先端のAIソリューションを提供することにに尽力しており、この度、オープンソースLLMモデルの包括的な評価結果をお届けできることを嬉しく思います。多くの企業が、透明性とカスタマイズ性の高さからオープンソース技術を採用する中、これらのモデルがGPT-4のようなクローズドソースの代替モデルと同等の性能を発揮できるのかという重要な疑問が残ります。
この疑問に答えるため、当社は最近公開したFlow Benchmark Toolを用いて、Recursiveが開発したテキスト生成、検索、および分析プラットフォームであるFindFlowに主要なオープンソースモデルを統合し、性能を徹底的に検証しました。
このテストでは、RAG(検索拡張生成)を用いた質問応答と、文書全体に対する理解という2つの重要な機能に焦点を当てました。これらの機能は、FindFlowのSearch AIとAnalysis AI機能の中心的な役割を果たしています。
オープンソースLLMモデルとは?
オープンソースLLMは、コード、アーキテクチャ、時にはトレーニングデータが公開されており、利用や変更、再配布が可能なモデルです。企業はこれらのモデルを活用することで、以下の3つの利点を得ることができます:
- カスタマイズ性:特定のニーズに合わせて調整が可能
- 透明性:モデルのアーキテクチャと内部構造を完全に可視化
- コスト効率:クローズドソースシステムに伴うサブスクリプション料金やAPIコストを排除
LLMモデルの比較:オープンソース vs. クローズドソース
Flow Benchmark Toolsの詳細
Recursiveは独自のFlow Benchmark Toolsを用いて、FindFlowのSearchAIやAnalysisAI機能を、Google、Microsoft、Metaといった大手企業が公開している複数のオープンソースLLMモデルでベンチマークテストを実施しました。
- SearchAIは、RAGを用いた質問応答に焦点を当てており、モデルが与えられたクエリの意図を正確に把握し、文脈に即した情報をどれだけ効果的に取得できるかを評価
- AnalysisAIは、文書全体の理解に重点を置いており、モデルが複雑で長文の文書からどれだけ効果的にインサイトを抽出できるかを評価
当社のツールは英語だけでなく、多言語でのモデル評価に対応しており、特に日本語への特化が特徴です。この多言語評価により、グローバルなアプリケーションにおいて、より実用的なベンチマーク結果を提供しています。
Flow Benchmark Toolsは、実際のシナリオを反映するよう、日本政府が公表しているあらゆる文書と、難易度の高い質問を含む日本の政府文書のデータセットを使用しています。GPT-4、Claude 3、Geminiなど、最先端のモデルを複数活用し、0(最低)から10(最高)までの値を持つ平均意見評価を出力します。
詳細については、当社の発表記事をご覧ください。
Flow Benchmark Toolsは、GitHubおよびPyPiで公開されています。
パフォーマンス概要:モデルサイズごとのオープンソースLLMモデルの評価
オープンソースのLLMモデルは、サイズによってパフォーマンスが大きく異なるため、モデルサイズごとに評価することが重要です。大規模、中規模、小規模のモデル間では性能に大きな差があり、特に複雑なタスクにおいては大規模モデルが優れた精度を発揮します。一方で中・小規模モデルはコスト効率に優れ、低いハードウェア要件の個人用コンピュータでも実行可能です。
性能のベンチマークとして、業界トップレベルのGPT-4oを基準に評価した結果、SearchAIで8.27、AnalysisAIで8.9という高スコアを達成しました。
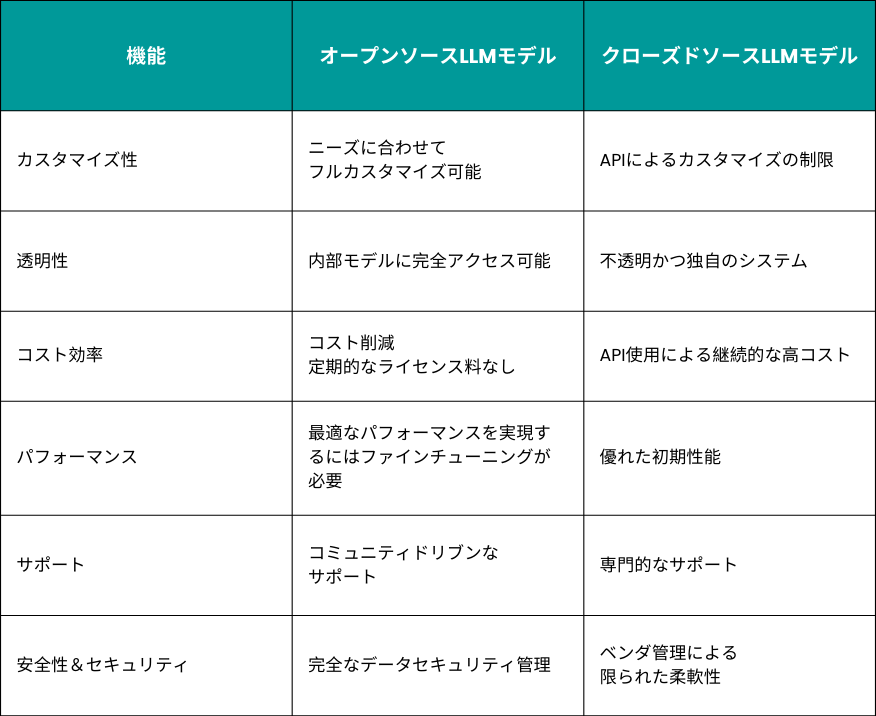
大規模モデル:主要なインサイト
- Llama 3.1-70B(Meta)とQwen 2.5-32B(Alibaba)は、大規模モデルの中で特に高い性能を提示。両モデルは、複雑なタスクにも対応できる強力な能力を備えている
- Llama 3.1-70Bは、特に英語での指示に従う能力が優れているが、日本語のサポートが内蔵されていないため、ファインチューニングによる改善が必要
- Mistral small-22B(Mistral AI)は、特に日本語のタスクにおいてAnalysisAIのスコアが低く、複雑な文書理解には不向きな側面が判明
- Gemma 2-27B(Google)は、特に大規模な文書を扱う際に全体的な性能が弱く、8,000トークンのコンテキストをサポートする設計だが、7,000トークンを超えると効果が低下し、複雑なタスクには不適切なであることが判明
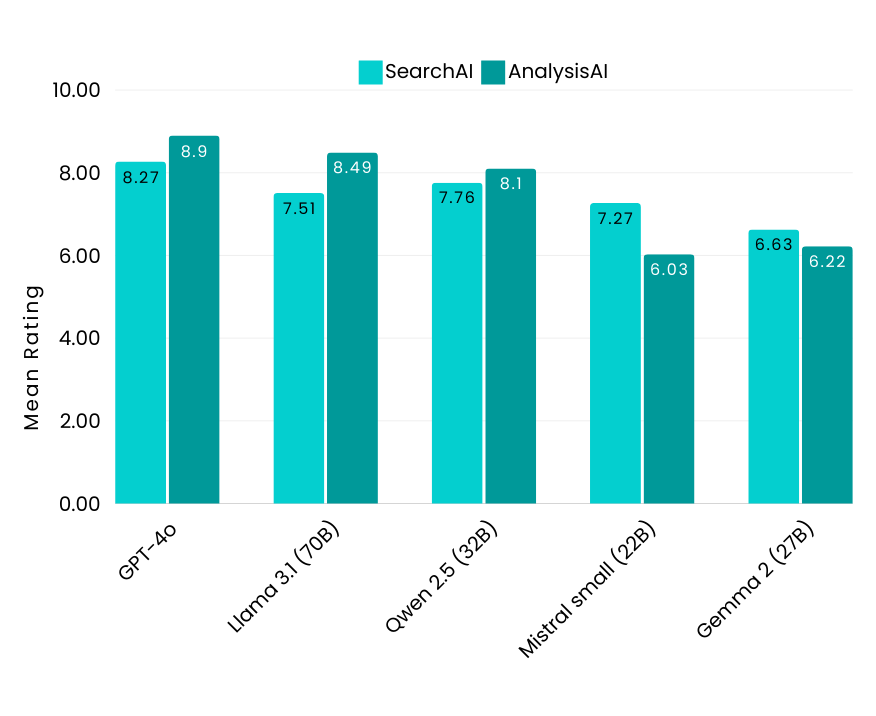
中規模モデル:主要なインサイト
- Qwen 2.5-14B(Alibaba)が中規模モデルの中で最も高い性能を示し、英語と日本語の両方のクエリに対して優れた結果を出した。特に、AnalysisAIで高いスコアを記録
- Mistral Nemo-12B(Mistral AI)は、英語のSearchAIで高いスコアを記録。日本語のSearchAIではスコアが低く、言語間の性能にばらつきが判明
- Phi-3-medium-14B(Microsoft)は他の中規模モデルと比較してAnalysisAIでの性能が低く、複雑な文書理解タスクの処理に限界があることが判明。また、日本語はサポート言語に含まれていないため、多言語分析の利用が制限されている
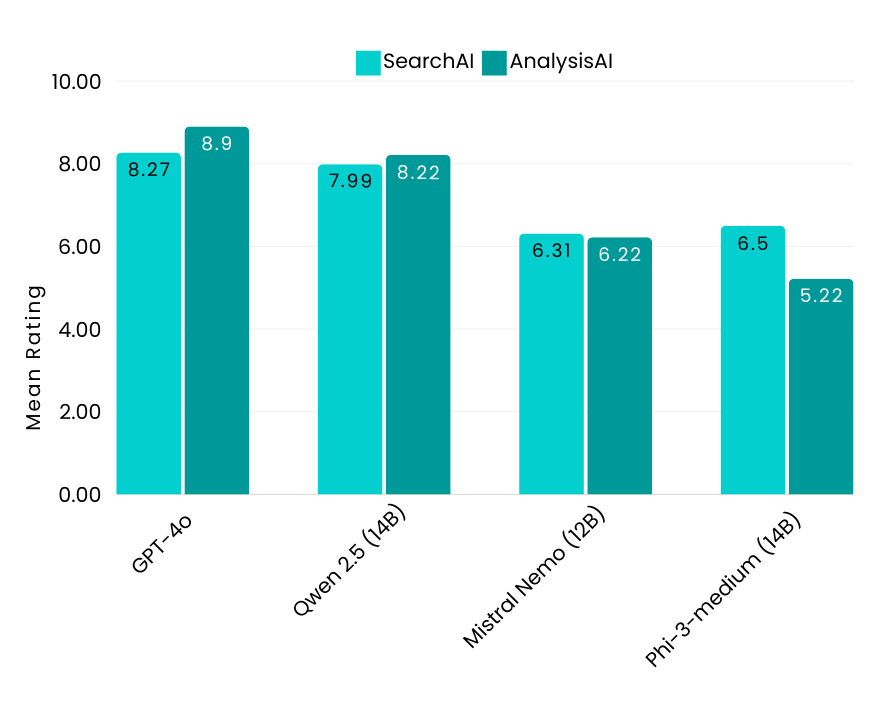
小規模モデル:主要なインサイト
- GLM4-9B(Zhipu AI)は、SearchAIおよびAnalysisAIタスクで多くの大規模モデルを上回るトップクラスの性能を提示
- Llama 3.1-8B(Meta)は、SearchAIにおいて着実な性能を提示。AnalysisAIにおいては、そのサイズに対しては適度の性能だが、日本語処理能力は他のモデルに比べて十分な水準に達していなかった。ファインチューニングにより、日本語のクエリ処理能力ををさらに改善ができるだろう
- Qwen 2.5-7B(Alibaba)は、サイズに対して優れたパフォーマンスを見せ、特定のタスクにおいて際立った結果を出し、小規模モデルのカテゴリーで競争力のあるモデルとなっている
- Gemma 2-9B(Google)は、他の小規模モデルと比較して性能が十分な水準に達していなかった。8,000トークンのコンテキストをサポートしているものの、5,000トークンを超えると性能が大幅に低下し、より要求の厳しいタスクや長文コンテンツの処理には課題を抱えている
オープンソースLLMの可能性とFindFlowの統合
Flow Benchmarkの結果は、3つのサイズカテゴリーにおけるオープンソースLLMモデルのトップパフォーマーを示しました。大規模モデルでは、Llama 3.1-70B(Meta)とQwen 2.5-32B(Alibaba)がSearchAIとAnalysisAIの両方で優れた性能を発揮しました。中規模モデルでは、Qwen 2.5-14B(Alibaba)が特に多言語対応の強みを発揮し、英語と日本語の両方で優れた結果を示しました。小規模モデルの中では、GLM4-9B(Zhipu AI)が精度と効率で大規模モデルを上回り、印象的な成果を上げました。
今回の評価結果では、オープンソースLLMは、クローズドソースモデルと同等の性能を発揮できることを明確にしました。当社のFindFlowのようなプラットフォームを活用することで、企業は柔軟かつコスト効率の高いAIソリューションを構築できるようになります。
FindFlowがどのようにして貴社の業務を月に20時間以上節約し、最適なプラットフォーム選びをサポートできるかを詳しく知りたい方は、sbdm@recursiveai.co.jpまでお問い合わせください。
Author

マーケティング・広報担当
Alina Paniuta
ウクライナ出身のアリーナは、台湾の国立政治大学で国際コミュニケーションの修士号を取得しました。台湾で4年間マーケティングマネージャーとして働いた後、2024年にRecursiveチームに加わり、憧れの国、日本での生活を体験するために日本に移住しました。



