Best Open-Source LLM Models: Flow Benchmark Results Revealed
AI2024-11-05

At Recursive, we are committed to delivering cutting-edge AI solutions, and today, we are excited to share the results of our extensive evaluation of open-source LLM models. As more businesses embrace open-source technologies for their transparency and customizability, one key question remains: Can these models match the performance of closed-source alternatives like GPT-4?
To address this, we used our recently launched Flow Benchmark Tools to thoroughly test the performance of leading open-source models by integrating them into FindFlow, a platform developed by Recursive for text generation, search, and analysis.
The tests focused on assessing two critical functions: question answering using retrieval-augmented generation (RAG) and whole document understanding. These capabilities form the core of our FindFlow platform as SearchAI and AnalysisAI features.
What Are Open-Source LLM Models?
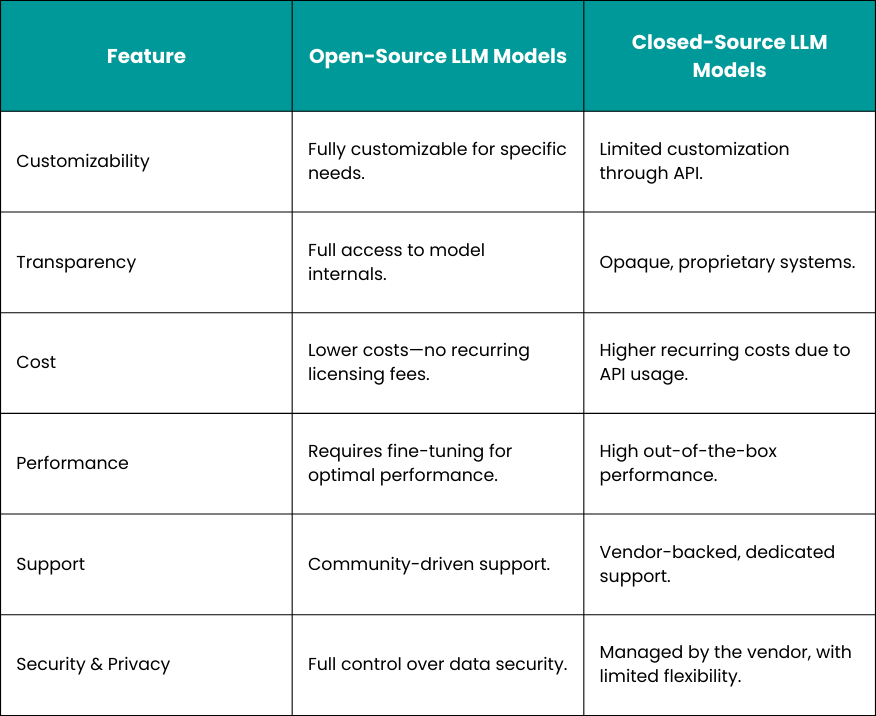
Open-source LLMs are publicly accessible models whose code, architecture, and sometimes training data are made available for use, modification, and redistribution. Businesses can leverage these models for their own applications, taking advantage of three key benefits:
- Customizability: Models can be fine-tuned to meet specific business needs.
- Transparency: Full visibility into the model’s architecture and inner workings.
- Cost Efficiency: Open-source models eliminate the need for subscription fees or API costs associated with closed-source systems.
Open-Source vs. Closed-Source LLM Models: A Quick Comparison
Flow Benchmark Tools: A Closer Look
To provide accurate and actionable insights, we used Recursive’s proprietary Flow Benchmark Tools to test SearchAI and AnalysisAI features of FindFlow on several open-source LLM models provided by top companies such as Google, Microsoft, Meta, and others.
- SearchAI focuses on question-answering using Retrieval-Augmented Generation (RAG), assessing how well models retrieve accurate, context-specific information from documents.
- AnalysisAI centers on whole document understanding, evaluating how effectively models extract insights from complex, full-length documents.
A unique feature of our tools is the multilingual capability, allowing us to evaluate model performance not only in English but also in other languages, with a specific focus on Japanese. This multi-language assessment makes our benchmarks particularly relevant for global applications.
The approach used in the Flow Benchmark Tools mirrors real-world use cases by utilizing a dataset of Japanese government documents with challenging questions to ensure a thorough evaluation. It employs a multi-model approach, including state-of-the-art models such as GPT-4, Claude 3, and Gemini, to generate objective results, with ratings from 0 (worst) to 10 (perfect). For more details, check out our launch announcement article.
Our Flow Benchmark Tools are publicly available on GitHub and PyPi.
Performance Overview: Evaluating Open-Source LLM Models by Size
It’s essential to analyze open-source LLM models by size, as performance varies significantly between big, medium, and small models. Larger models generally deliver superior accuracy, especially in complex tasks, while smaller models offer a cost-efficient solution, capable of running on personal computers with lower hardware requirements.
To establish a performance benchmark, we included GPT-4o, a closed-source model renowned for its strong capabilities. When integrated with FindFlow, it achieved impressive scores of 8.27 for SearchAI and 8.9 for AnalysisAI.
Big Size Models: Key Insights
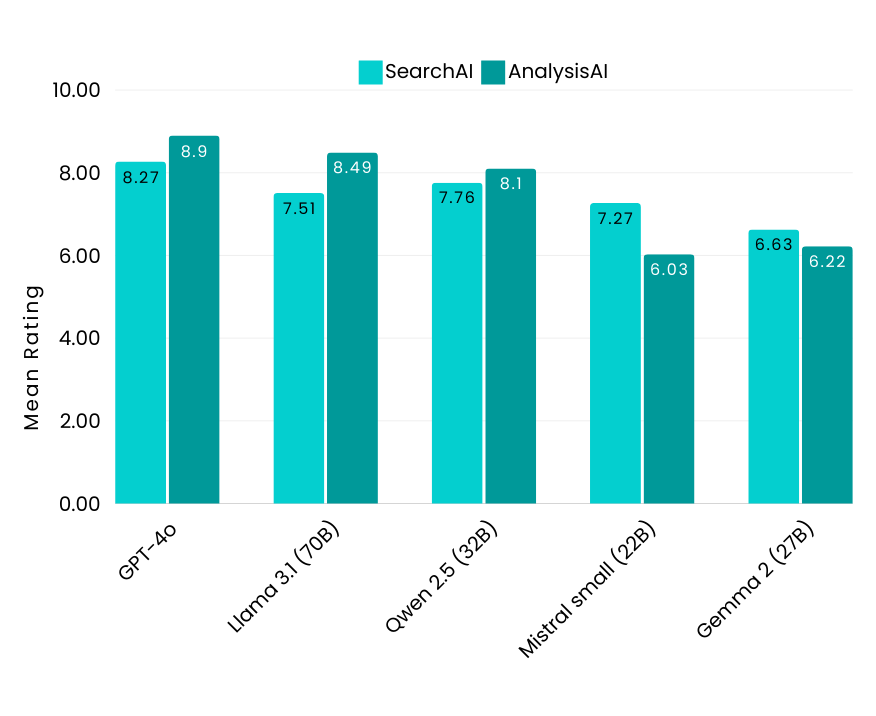
- Llama 3.1-70B (Meta) and Qwen 2.5-32B (Alibaba) emerged as top performers among the larger models. Both demonstrated robust capabilities, making them ideal for more complex tasks.
- Llama 3.1-70B showed particularly strong instruction-following in English but lacked built-in support for Japanese, which could be improved through fine-tuning.
- Mistral small-22B (Mistral AI) delivered lower scores in Analysis AI, especially for Japanese tasks, limiting its effectiveness in complex document understanding.
- Gemma 2-27B (Google) showed weaker overall performance, particularly when handling larger documents. By design, it supports an 8,000-token context length, which is significantly lower than other models. However, its effectiveness drops when the context exceeds 7,000 tokens, limiting its capability for complex tasks.
Medium Size Models: Key Insights
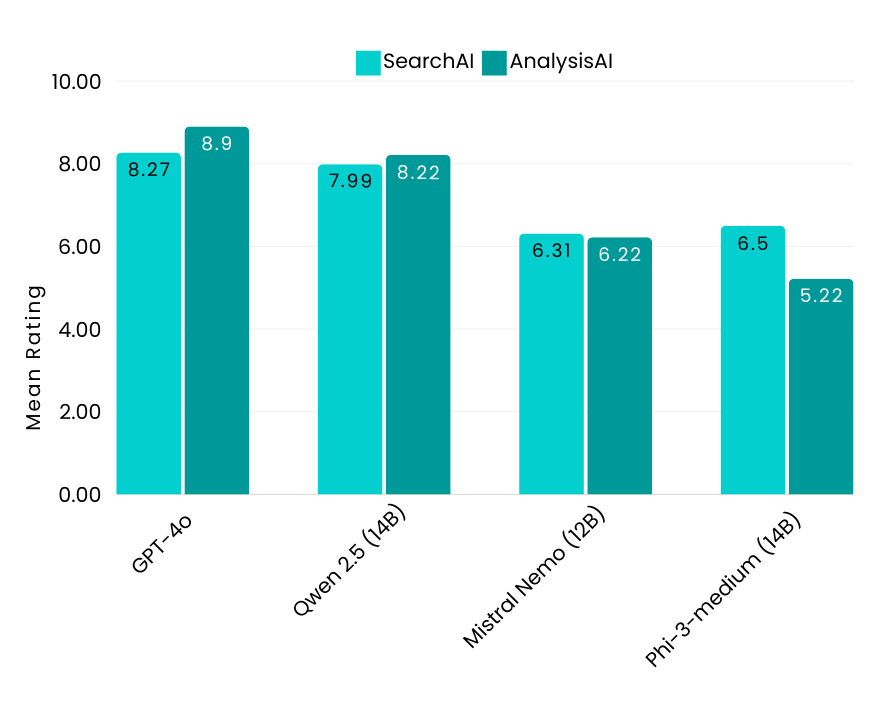
- Qwen 2.5-14B (Alibaba) led the medium-size category, delivering strong results in both English and Japanese queries, with particularly high AnalysisAI scores.
- Mistral Nemo-12B (Mistral AI) showed strong English SearchAI scores but lagged in Japanese SearchAI, indicating inconsistencies across languages.
- Phi-3-medium-14B (Microsoft) underperformed in AnalysisAI compared to other mid-size models, highlighting limitations in handling complex document understanding tasks. Additionally, Japanese is not on the list of supported languages, restricting its usefulness for multilingual analysis.
Small Size Models: Key Insights
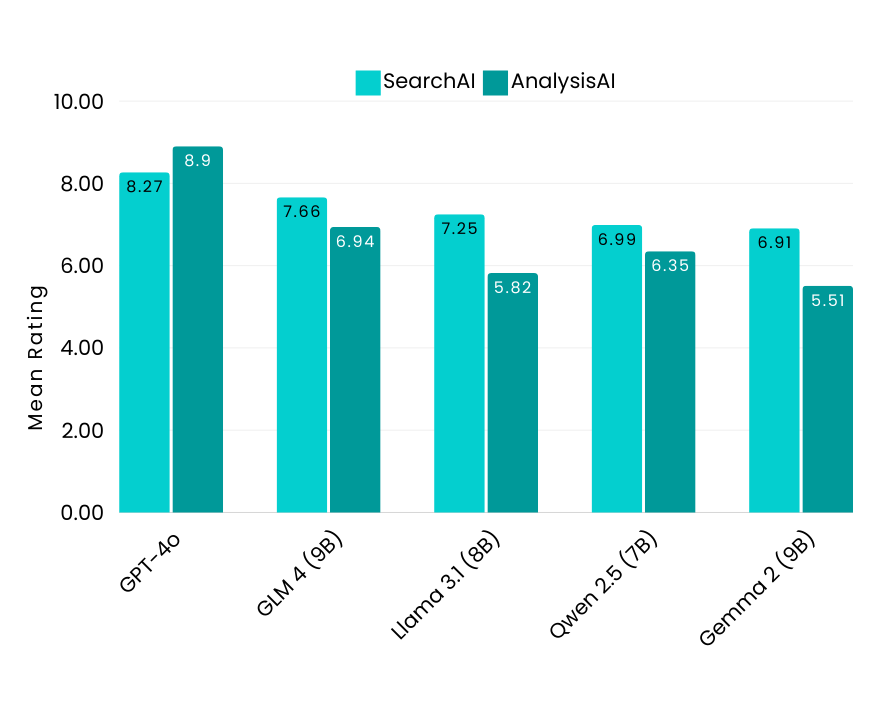
- GLM4-9B (Zhipu AI) demonstrated top-tier performance, surpassing many larger models in SearchAI and AnalysisAI tasks.
- Llama 3.1-8B (Meta) showed solid performance in SearchAI. In AnalysisAI, it performed moderately well for its size, but its Japanese capabilities lagged behind. Fine-tuning could enhance its ability to process Japanese queries more effectively.
- Qwen 2.5-7B (Alibaba) showed respectable performance relative to its size, excelling in certain tasks, making it a competitive model in the small-size category.
- Gemma 2-9B (Google) underperformed compared to other small models. Although it supports an 8,000-token context length, its effectiveness significantly declines beyond 5,000 tokens, posing challenges for handling more demanding tasks or long-form content.
Open-Source LLMs Show Promise with the Right Integration
Our Flow Benchmark results showcased the top-performing open-source LLM models across three size categories. For big-size models, Llama 3.1-70B (Meta) and Qwen 2.5-32B (Alibaba) excelled in both SearchAI and AnalysisAI. In the medium category, Qwen 2.5-14B (Alibaba) stood out, particularly for its multilingual strengths, performing well in both English and Japanese. Among small models, GLM4-9B (Zhipu AI) impressed by outperforming larger models in accuracy and efficiency.
These findings show that with the right integration—like our FindFlow platform—open-source LLMs can achieve performance on par with closed-source models while providing greater flexibility and cost savings.
To discover how FindFlow can save your business 20+ hours a month and guide you in selecting the best platform, reach out to us at sbdm@recursiveai.co.jp.
Author

Marketing and PR Associate
Alina Paniuta
Originally from Ukraine, Alina earned her Master’s degree in International Communications from National Chengchi University (Taiwan). After four years in Taiwan working as a Marketing Manager, she relocated to Japan in 2024 to join the Recursive team and experience life in her dream country.



